

Bug

Links




Accès rapide :
La vidéo
Qu'est-ce qu'une expression régulière ?
Les différents langages d'expressions régulières
Exemples de vérification d'un format d'email
Un premier exemple très simpliste
Vérifications de format d'email plus robustes
Petite variation sur le même thème
Quelques compléments de syntaxe
Exemples de vérification d'un format de date
Un premier exemple très simpliste
Vérifications de format de date plus robustes
Les expressions régulières, est-ce un bon choix ?
Travaux pratiques
Le sujet
La correction
Cette vidéo vous permet de mettre en oeuvre vos premières expressions régulières en Java. Des exemples de vérifications de formats d'emails ou de dates vous sont proposés.
Une expression régulière est un ensemble de caractères particuliers (formant le langage d'expressions régulières), appelé un format (ou bien motif, ou encore pattern en anglais), qui permet de décrire un ensemble de chaînes de caractères à reconnaître. Par exemple, on peut décrire l'ensemble des emails autorisés (ce qui correspond à un très grand nombre de chaînes de caractères possibles) avec une expression régulière.
Une expression régulière nous permet, une fois définie, les traitements suivants :
la mise en correspondance (matching, en anglais) : permet, par exemple, de vérifier si une chaîne de caractères saisie par un utilisateur correspond bien à un email (du moins si elle « match » avec le format d'email spécifié).
la substitution : permet de remplacer une ou plusieurs occurrences de l'expression régulière par une autre chaîne de caractères. Dans le cas où la chaîne de caractères de substitution est chaîne vide, on réalise alors de la suppression d'occurrences.
l'extraction de données : permet de repérer une sous chaîne de caractères, répondant à un format donné (un email, pourquoi pas), et de récupérer cette sous-chaîne dans votre code pour la traiter.
Dans ce premier chapitre, dédié aux expressions régulières, nous ne traiterons que du premier point : la mise en correspondance. Les autres possibilités seront étudiées dans les chapitres suivants.
Là ou ça se complique, c'est qu'il existe différents langages d'expressions régulières. Dans ces différents langages, un caractère peut avoir des sens différents.
A l'origine, ces formalismes ont été définis pour le fonctionnement de différentes commandes d'un système Linux/Unix (sed, grep, ...). Par la suite on a commencé à retrouver ces possibilités directement dans nos langages de programmation favoris.
Parmi les principaux standards d'expressions régulières, on retrouve :
Les expressions régulières POSIX : ce format est définit dans le standard POSIX (Portable Operating System Inteface, le X étant pour XWindow) à la base des divers systèmes Unix/Linux.
Les expressions régulières BRE (Basic Regular Expressions) : une forme simplifiée de langage d'expressions régulières.
Les expressions régulières ERE (Extended Regular Expressions) : une forme intermédiaire de langage d'expressions régulières.
Les expressions régulières PCRE (Perl Compatible Regular Expressions) : un formalisme relativement riche, introduit dès la version 2.0 du langage Perl. Fort de son succès, ce formalisme à été repris par de nombreux langages de programmation et notamment Java.
-E ou -P).
$> man grep
GREP(1) General Commands Manual GREP(1)
NAME
grep, egrep, fgrep - print lines matching a pattern
SYNOPSIS
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] -e PATTERN ... [FILE...]
grep [OPTIONS] -f FILE ... [FILE...]
DESCRIPTION
grep searches for PATTERN in each FILE. ....
...
OPTIONS
...
Matcher Selection
-E, --extended-regexp
Interpret PATTERN as an extended regular expression (ERE, see below).
-F, --fixed-strings
Interpret PATTERN as a list of fixed strings (instead of regular expressions),
separated by newlines, any of which is to be matched.
-G, --basic-regexp
Interpret PATTERN as a basic regular expression (BRE, see below).
This is the default.
-P, --perl-regexp
Interpret the pattern as a Perl-compatible regular expression (PCRE).
This is experimental and grep -P may warn of unimplemented features.
...
$>
Afin de mieux comprendre ce concept, nous allons maintenant voir un exemple concret. Nous allons chercher à vérifier si une chaîne de caractères, saisie par l'utilisateur, correspond oui ou non à un email.
Nous allons tester différentes expressions régulières pour tester nos emails. La première sera très permissive. Ensuite, nous essayerons de renforcer nos vérifications.
Donc, dans le souci de commencer simplement, je vous propose cette première expression régulière, et là je sens que vous commencez à faire la grimace ;-).
^.+@.+\..+
Les choses sont plus simples qu'il n'y parait. Reprenons cette expression, partie par partie.
^ : indique que la chaîne, validée par cette expression régulière, doit commencer par le contenu de l'expression et qu'il ne doit rien y avoir
avant. Effectivement, le matching dit si le pattern recherché est présent dans la chaîne à valider. Si on ne veut pas vérifier la présence, mais
plutôt valider l'exactitude du motif, alors il faut spécifier qu'on accepte rien devant (^) et rien derrière ($) le motif.
. : ce caractère « match » avec n'importe quel caractère, sauf retour à la ligne. Si l'on considère la partir de gauche d'un
email, avant le caractère @, on peut effectivement avoir n'importe quelle lettre ou n'importe quel chiffre ou bien encore d'autres
caractères tels que _, - ou encore .. L'élément de syntaxe . du langage d'expression régulière
englobe donc bien toutes ces possibilités.
+ : ce caractère fait partie de la famille de caractères de répétition. Il s'applique à l'élément précédent (donc ici le .)
et indique qu'on devra répéter cet élément au moins une fois (1..*). Dit autrement, la partie gauche d'un émail (avant le caractère @)
devra contenir au moins un caractère.
@ : ce caractère passe pour lui-même et n'a donc pas de signification particulière dans le langage d'expression régulière.
C'est suffisamment rare pour que cela puisse être remarqué. ;-)
.+ : pareil que précédemment, pour la partie gauche du nom de domaine.
\. : on dé-spécialise le caractère .. Du coup, il passe pour lui-même : c'est le point que l'on retrouve à la fin de
l'adresse email et par exemple .fr ou .com.
.+ : pareil que précédemment, pour la partie droite du nom de domaine.
$ : indique que la chaîne, validée par cette expression régulière, doit finir par le contenu de l'expression et qu'il ne doit rien y avoir après.
Maintenant testons cette expression dans un bout de code Java. Pour ce faire, nous allons utiliser, dans un premier temps car il y a mieux,
la méthode String.matches. Elle permet de vérifier si une chaîne de caractères correspond à un pattern particulier.
\ a un sens particulier dans le langage d'expression régulière. Mais il en a aussi un (quasi similaire) en Java.
Les deux langages (expressions régulières et Java) peuvent donc rentrer en collision quand ils sont utilisés conjointement.
Il est donc nécessaire de dé-spécialisé ce caractère (le doubler) en Java quand on veut le rendre opérationnel dans le langage d'expressions régulières.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class RegExpMatching { public static boolean isValidEmail( String email ) { String regExp = "^.+@.+\\..+$"; // Notice the sequence \\ return email.matches( regExp ); } public static void main(String[] args) { // --- Good Emails --- System.out.println( isValidEmail( "dominique.liard@infini-software.com" ) ); System.out.println( isValidEmail( "martin@societe.com" ) ); System.out.println( isValidEmail( "martin@societe.fr" ) ); System.out.println( "-----------------------------" ); // --- Bad Emails --- System.out.println( isValidEmail( "martin.societe.com" ) ); // No @ character System.out.println( isValidEmail( "martin@societe" ) ); // No . character //System.out.println( isValidEmail( "martin@societe.f" ) ); //System.out.println( isValidEmail( "@@@.@" ) ); } } |
Et voici les résultats produit par l'exemple ci-dessus.
$> java RegExpMatching true true true ----------------------------- false false $>
Au premier abord, cela parait pas trop mal. Ce qui ne ressemble pas trop à un email semble avoir était rejeté.
Pour autant, vous avez peut-être remarqué les deux dernières lignes du main : elles sont commentées.
Que se passe-t-il si on les dé-commente ? Et bien ça dit notamment que "@@@.@" est un email correct. Mince !
Cela vient du fait que notre expression régulière n'est pas assez restrictive et plus précisément de l'utilisation du caractère .,
qui je le rappelle accepte n'importe quoi, sauf retour à la ligne. En conséquence la chaîne "@" est valide en tant que partie
gauche de l'adresse email. Il faut revoir ce point !
Nous allons donc restreindre les possibilités acceptées (et en tout cas, ne plus dire n'importe quoi). Que peut-on avoir comme caractères valides en
partie gauche. Nous allons simplifier les choses et nous allons dire : les lettres (minuscules et majuscules), les chiffres, le _, le
- et le .. Pour identifier ces caractères nous allons utiliser la syntaxe « ensemble de caractères » introduite par
des caractères crochets ([]). Voici le nouveau code Java avec les deux dernières lignes dé-commentées.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public class RegExpMatching { public static boolean isValidEmail( String email ) { //String regExp = "^.+@.+\\..+$"; String regExp = "^[A-Za-z0-9._-]+@[A-Za-z0-9._-]+\\.[a-z][a-z]+$"; return email.matches( regExp ); } public static void main(String[] args) { // --- Good Emails --- System.out.println( isValidEmail( "dominique.liard@infini-software.com" ) ); System.out.println( isValidEmail( "martin@societe.com" ) ); System.out.println( isValidEmail( "martin@societe.fr" ) ); System.out.println( "-----------------------------" ); // --- Bad Emails --- System.out.println( isValidEmail( "martin.societe.com" ) ); // No @ character System.out.println( isValidEmail( "martin@societe" ) ); // No . character System.out.println( isValidEmail( "@@@.@" ) ); System.out.println( isValidEmail( "martin@societe.f" ) ); } } |
C'est la séquence [A-Za-z0-9._-]+ qui permet de gérer la partie gauche de l'email. Le caractère + permet donc de répéter
autant de fois que nécessaire un caractère parmi l'ensemble [A-Za-z0-9._-]. Comme vous le constatez, on peut utiliser des intervalles,
bien plus pratique que de fournir l'ensemble des caractères utilisés ([a-z] VS [abcdefghijklmnopqrstuvwxyz]).
a-z et A-Z sont bien différents. Le premier correspond aux lettres minuscules alors que le second
correspond aux lettres majuscules. Si vous souhaitez les deux intervalles, il faut alors les spécifier tous les deux.
Par contre, ce langage est fourbe ! L'intervalle [A-Za-z0-9._-] est différent de l'intervalle [A-Za-z0-9.-_].
La subtilité se trouve sur les trois derniers caractères de l'intervalle. Ce qui est source d'erreur c'est qu'un même caractère peut avoir un
sens différent en fonction de là ou il est utilisé. Et c'est exactement ce qui se passe dans le cas présent. Si le caractère -, utilisé dans
un ensemble de caractères (entre []), est placé en premier ou en dernier, alors il correspond à lui-même : vous autorisez donc le caractère
- dans la séquence. Par contre, s'il est placé entre deux caractères, alors il prend le sens « intervalle ».
Un intervalle démarre du code ASCII du premier caractère et va jusqu'au code ASCII du dernier caractère. Du coup, méfiez-vous de cet ensemble de valeurs :
[A-Za-z0-9._-]. Il permet tous les caractères ASCII compris entre le . (de code ASCII 46) et le _ (de code ASCII 95) et entre autre les caractères suivants
>=<?.... A titre de rappel, voici l'ensemble des caractères ASCII (source Wikipedia).
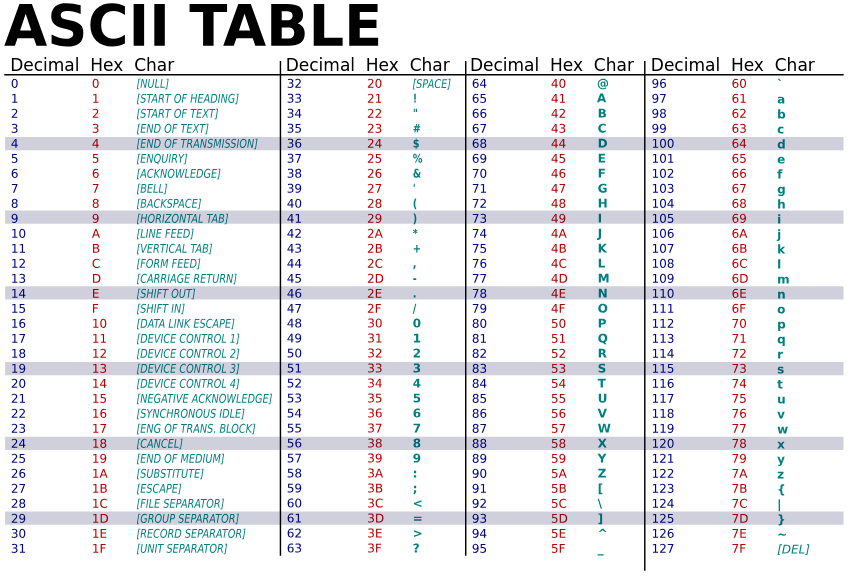
[z-a] ne sera pas supporté par le moteur d'évaluation d'expression régulière et une erreur d'exécution sera produite.
Le premier caractère de l'intervalle doit avoir un code ASCII inférieur à celui du dernier caractère de l'intervalle. Par contre, [a-z]
fonctionne très bien. Du coup, vous ne pouvez pas évaluer non plus l'ensemble _-. : voici le message d'erreur produit.
$> java RegExpMatching
Exception in thread "main" java.util.regex.PatternSyntaxException: Illegal character range near index 13
^[A-Za-z0-9_-.]+@[A-Za-z0-9._-]+\.[a-z][a-z]+$
^
at java.util.regex.Pattern.error(Pattern.java:1955)
at java.util.regex.Pattern.range(Pattern.java:2655)
at java.util.regex.Pattern.clazz(Pattern.java:2562)
at java.util.regex.Pattern.sequence(Pattern.java:2063)
at java.util.regex.Pattern.expr(Pattern.java:1996)
at java.util.regex.Pattern.compile(Pattern.java:1696)
at java.util.regex.Pattern.<init>(Pattern.java:1351)
at java.util.regex.Pattern.compile(Pattern.java:1028)
at java.util.regex.Pattern.matches(Pattern.java:1133)
at java.lang.String.matches(String.java:2121)
at RegExpMatching.isValidEmail(RegExpMatching.java:6)
at RegExpMatching.main(RegExpMatching.java:13)
$>
Autre remarque importante, nous avons souhaité que la partie finale de l'email (après le dernier caractère .) comporte au moins deux
caractères. Pour y arriver, nous avons utilisé une première solution : [a-z][a-z]+. Le premier intervalle dit qu'on souhaite avoir une lettre
(et obligatoirement une) suivie d'au moins une fois une autre lettre (second intervalle avec le caractère de répétition +).
On aura donc bien au moins deux lettres.
Voici les résultats produit par l'exemple proposé plus haut.
$> java RegExpMatching true true true ----------------------------- false false false false $>
Ce qui ne simplifie pas la chose, c'est que parfois vous avez des syntaxes différentes, mais équivalente. L'exemple que nous allons proposer dans quelques instants réalisera très exactement les mêmes vérifications.
Premier point, l'ensemble [a-zA-Z0-9_] peut être remplacer par \w. La minuscule est importante car \W correspond
à tout sauf [a-zA-Z0-9_], aussi exprimé sous la forme [^a-zA-Z0-9_] (le caractère ^ en première position dans
un ensemble signifiant « tout sauf »).
\w (w pour word, il s'agit donc de caractères de mot) comprend le caractère _. Cela vient du fait
qu'à l'origine, on cherchait à parser (à découper) du code écrit en langage C. Et dans la syntaxe C (comme en Java d'ailleurs), un identifiant (nom
de variable ou nom de fonction) peut contenir ce caractère.
Second point, la partie [a-z][a-z]+ peut aussi s'écrire [a-z]{2,} (de minimum 2, jusqu'à l'infini).
En conséquence, on peut réécrire le programme précédent ainsi :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public class RegExpMatching { public static boolean isValidEmail( String email ) { //String regExp = "^.+@.+\\..+$"; //String regExp = "^[A-Za-z0-9._-]+@[A-Za-z0-9._-]+\\.[a-z][a-z]+$"; String regExp = "^[\\w.-]+@[\\w.-]+\\.[a-z]{2,}$"; return email.matches( regExp ); } public static void main(String[] args) { // --- Good Emails --- System.out.println( isValidEmail( "dominique.liard@infini-software.com" ) ); System.out.println( isValidEmail( "martin@societe.com" ) ); System.out.println( isValidEmail( "martin@societe.fr" ) ); System.out.println( "-----------------------------" ); // --- Bad Emails --- System.out.println( isValidEmail( "martin.societe.com" ) ); // No @ character System.out.println( isValidEmail( "martin@societe" ) ); // No . character System.out.println( isValidEmail( "@@@.@" ) ); System.out.println( isValidEmail( "martin@societe.f" ) ); } } |
Les résultats produits seront les mêmes que précédemment.
Voici donc une liste complémentaire de possibilités offertes pas les expressions régulières.
\w : équivalent à [a-zA-Z0-9._-]
\W : équivalent à [^a-zA-Z0-9._-] (tout, sauf [a-zA-Z0-9._-])
\d : équivalent à [0-9]
\D : équivalent à [^0-9] (tout, sauf [0-9])
\s : un séparateur (blanc, tab, ...)
\S : tout, sauf un séparateur
+ : au moins une fois
* : un nombre de fois quelconque, y compris 0
? : zéro ou une fois
{2,8} : de deux à huit fois
{2,} : au moins deux fois
{,8} : huit fois au maximum
Nous allons maintenant cherché à vérifier si une chaîne de caractères contient bien une date aux formats suivants : jj/mm/aaaa ou
jj/mm/aa. Dit autrement, on veut d'abord le numéro de jour sur deux chiffres, puis celui du mois sur deux chiffres et, enfin, l'année
sur deux chiffres ou sur quatre chiffres.
Je vous propose en premier exemple, le code suivant. Qu'en pensez-vous ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public class RegExpMatching { public static boolean isValidDate( String date ) { // jj/mm/aaaa jj/mm/aa String regExp = "^\\d\\d/\\d\\d/\\d\\d(\\d\\d)?$"; // ou String redExp = "^[0-9]{2}/[0-9]{2}/([0-9]{2})?[0-9]{2}$"; return date.matches( regExp ); } public static void main(String[] args) { // --- Good Dates --- System.out.println( isValidDate( "30/05/2017" ) ); System.out.println( isValidDate( "30/05/17" ) ); System.out.println( "-----------------------------" ); // --- Bad Dates --- System.out.println( isValidDate( "30/05/017" ) ); System.out.println( isValidDate( "30/5/17" ) ); System.out.println( isValidDate( "3/05/17" ) ); } } |
Les résultats produits par cet exemple sont les suivants :
$> java RegExpMatching true true ----------------------------- false false false $>
C'est pas mal, mais on peut mieux faire ! Pourquoi ?
Le problème réside dans le fait qu'on ne contrôle que la présence de nombres, mais pas le fait qu'ils sont dans un intervalle de valeurs correct. Par exemple, notre expression régulière reconnaît sans problème la chaîne "45/23/9018" : je pense, malgré cela, qu'on peut dire que la date n'est pas bonne (le 45ième jour du 23ième mois ???).
Il faut comprendre que le langage d'expressions régulières n'est pas un langage de programmation : il permet juste de reconnaître un motif (pattern).
Il est donc impossible d'écrire un truc du genre >=1 and <=31. Par contre, on peut quand même être malin et affiner nos tests.
Plutôt que d'écrire [0-9]{2}, qui accepte n'importe quelles valeurs entières (sur deux chiffres) comprise entre 00 et 99, que pensez-vous
de l'expression [0-3][0-9] ? Comme il y a deux paires de crochets, on accepte bien deux chiffres, mais le premier est restreint à des
valeurs comprises entre 0 et 3. C'est mieux, non ?
Mais on peut encore faire mieux. Avec la séquence [0-3][0-9], on accepte encore les valeurs 00, 32, 33, ... On peut les rejeter !
Comment, en utilisant un nouveau caractère du langage d'expressions régulières : le pipe (|) qui veut dire « ou bien ».
Utilisé conjointement avec des parenthèses, il permet d'écrire des expressions conditionnelles. Que pensez-vous de l'expression régulière suivante ?
String regExp = "^(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19|20)?[0-9]{2}$";
Normalement, seules de valeurs comprises en 01 et 31 seront acceptées pour le numéro de jour et seules des valeurs comprises entre 01 et 12 seront acceptées pour le numéro de mois. Notez même qu'on a limité l'information de siècle à 19 ou 20 (pour peu que ce soit judicieux, bien entendu).
Voici une nouvelle version, plus stricte, de notre programme de vérification de dates.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
public class RegExpMatching { public static boolean isValidDate( String date ) { // jj/mm/aaaa jj/mm/aa String regExp = "^(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19|20)?[0-9]{2}$"; return date.matches( regExp ); } public static void main(String[] args) { // --- Good Dates --- System.out.println( isValidDate( "30/05/2017" ) ); System.out.println( isValidDate( "30/05/17" ) ); System.out.println( "-----------------------------" ); // --- Bad Dates --- System.out.println( isValidDate( "00/10/1999" ) ); System.out.println( isValidDate( "36/10/1999" ) ); System.out.println( isValidDate( "26/00/1999" ) ); System.out.println( isValidDate( "26/13/1999" ) ); System.out.println( isValidDate( "30/05/017" ) ); System.out.println( isValidDate( "30/5/17" ) ); System.out.println( isValidDate( "3/05/17" ) ); System.out.println( isValidDate( "martin@societe.com" ) ); System.out.println( isValidDate( "jj/mm/aaaa" ) ); } } |
Et voici les résultats produits par cet exemple :
$> java RegExpMatching true true ----------------------------- false false false false false false false false false $>
Imaginez le même programme écrit sans expression régulière et uniquement avec des appels à des méthodes de la classe String.
Pour arriver au même résultat que la méthode isValidEmail, il nous faudrait environ deux pages de code.
Donc, oui les expressions régulières sont une bonne alternative de par leur compacité. Faire sans peut s'avérer bien plus compliqué. Le point noir étant la lisibilité, et donc la compréhension, du code produit : une personne non sensibilisée à l'utilisation des expressions régulières pourra rester bloquée sur ce genre de code.
Dans le but de vous entraîner, je vous propose de vérifier si des adresses réseaux sont bien exprimées au format IPv4. Pour rappel, une adresse IPv4 est constituée de 4 octets (donc de valeur comprise entre 0 et 255) séparés par un point. Voici quelques exemples d'adresses IPv4 valides.
127.0.0.1 192.168.1.100 75.78.10.3
En vous inspirant de la dernière expression régulière proposée pour la validation des dates, essayez de me proposer une expression régulière de vérification d'adresses IPv4. Encore une fois, ne passez pas directement à la correction : attention, je vous surveille ;-)
Voici une proposition de correction pour valider (ou non) quelques adresses IPv4. Notez bien la manière de répéter trois fois un octet suivit d'un point. Notez aussi l'utilisation des parenthèses pour forcer les priorités.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public class RegExpMatching { public static boolean isValidAddress( String address ) { String octet = "[0-9]|[0-9]{2}|[0-1][0-9]{2}|2[0-4][0-9]|25[0-5]"; String regExp = "^((" + octet + ")\\.){3}(" + octet + ")$"; return address.matches( regExp ); } public static void main(String[] args) { // --- Good IPv4 addresses --- System.out.println( isValidAddress( "127.0.0.1" ) ); System.out.println( isValidAddress( "192.168.1.100" ) ); System.out.println( isValidAddress( "75.78.10.3" ) ); System.out.println( "-----------------------------" ); // --- Bad IPv4 addresses --- System.out.println( isValidAddress( "256.1.2.3" ) ); System.out.println( isValidAddress( "0.256.2.3" ) ); System.out.println( isValidAddress( "0.1.256.3" ) ); System.out.println( isValidAddress( "0.1.2.256" ) ); System.out.println( isValidAddress( "0,1,2,3" ) ); } } |

 Mise en oeuvre de méthodes récursives
Mise en oeuvre de méthodes récursives
 Compilation d'expressions régulières
Compilation d'expressions régulières
Améliorations / Corrections
Vous avez des améliorations (ou des corrections) à proposer pour ce document : je vous remerçie par avance de m'en faire part, cela m'aide à améliorer le site.
Emplacement :
Description des améliorations :