

Bug

Links




ATTENTION : Tutorial en cours d'écriture ! N'hésiter pas à nous signaler toute erreur ou suggestion.
Nous allons, dans ce chapitre, étudier la syntaxe du langage XML. En effet, un fichier XML utilise des tags pour structurer ses données. Différentes règles existent pour régirent l'utilisation de ces tags. Nous allons donc les présenter une par une.
Nous parlerons aussi de certains autres aspects inhérent à la mise en oeuvre d'un document XML. Et notamment : la notion de prologue, celle de namespaces ainsi que tout ce qui à attrait au tables de codage de caractères.
A l'instar d'HTML, le langage XML utilise aussi des tags (on parle aussi, en français, de marques ou de balises). Un tag est facilement reconnaissable étant donné qu'il commence par le caractère < et qu'il se termine par le caractère >. Mais cette simple définition ne suffit pas à définir XML. En effet, les choses sont un peu plus complexes : c'est ce que nous allons développer dans cette section.
Premièrement, sachez qu'il y a une distinction entre les tags ouvrant et les tags fermant. Si nous reprenons l'exemple du langage FML (vu dans le chapitre précédent), le tag <CHAPITRE> est un tag ouvrant alors que le tag </CHAPITRE> est un tag fermant. Un tag fermant commence par les deux caractères </.
Tout tag ouvrant doit obligatoirement être fermé plus loin dans le fichier. Pour une personne qui à l'habitude d'HTML, cette règle est nouvelle. En effet en HTML, un tag peut ne pas être fermé : par exemple le tag <HR> (Horizontal Rule), qui permet de tracer une ligne horizontale de séparation, n'a pas de tag fermant. En XML, il en va autrement : si le fichier est syntaxiquement incorrect, le traitement du fichier aboutira à une erreur. La capture d'écran suivante montre le cas d'un fichier XML contenant un tag non fermé qui serait affiché dans Internet Explorer.
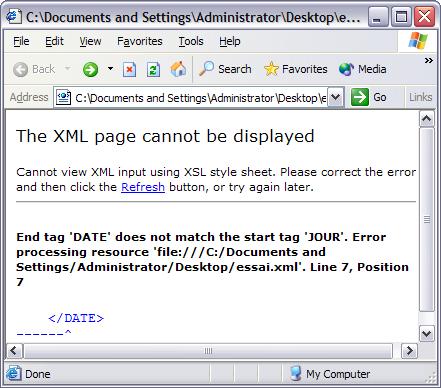
Il existe cependant une forme plus compacte pour représenter un couple de tags XML ne contenant pas de données. Il suffit du fournir un unique tag commençant par le caractère < et se terminant par les caractères /> (cette fois-ci, le slash (/) est positionné à la fin du tag). Ce tag est lors à la fois ouvrant et fermant. Les deux lignes suivantes sont syntaxiquement équivalente si l'on considère avoir utilité d'un tag <DATE> prenant trois attributs.
<DATE Jour="26" Mois="08" Année="1973"></DATE> <DATE Jour="26" Mois="08" Année="1973" /> |
Secundo, XML fait une distinction entre les lettres minuscules et les lettres majuscules. Encore un fois, l'expert HTML devra s'adapter à cette nouvelle règle, dans le sens ou HTML ne fait pas la distinction entre ces deux types de lettres. Les exemples suivants sont tous, syntaxiquement, incorrects. Si vous affichez un tel document dans IE, un message d'erreur vous sera retourné.
<DATE Jour="26" Mois="08" Année="1973"></date> <Date Jour="26" Mois="08" Année="1973"></date> <DaTe Jour="26" Mois="08" Année="1973"></dAtE> |
En dernier lieu, notez que vous ne pouvez pas choisir n'importe quoi comme nom de tags. Certes, XML ne définit aucun tag, mais vos noms ne doivent pas commencer par le mot xml (en minuscules). Ainsi, au cas ou dans l'avenir, un quelconque tag doit être défini, au niveau de la recommandation XML (aujourd'hui en version 1.0), il commencera par ce préfixe.
Hormis cette règle, vous pouvez opter pour le nom de votre choix en sachant que ce dernier ne devra contenir que des lettres, des chiffres, et les caractères - (trait d'union), _ (underscore), . (le point) et : (deux points). Sachez, en outre, que ce dernier caractère a une signification particulière (introduction d'un namespace, nous en reparlerons) et que vos noms ne peuvent commencer que par un underscore ou une lettre.
Une règles importante à garder à l'esprit est la règle d'imbrication des tags. Vous ne pouvez pas utiliser les tags n'importe comment les uns par rapports aux autres. Nous savons déjà que tout tag ouvrant doit avoir un tag fermant lui correspondant. Mais cela ne suffit pas.
Vos tags ne devrons en aucun cas se chevaucher, sans quoi le document ne sera pas syntaxiquement correcte. L'exemple suivant n'est donc pas correcte.
<TAG-PARENT>
<TAG-ENFANT>
</TAG-PARENT>
</TAG-ENFANT>
|
Vos tags se doivent obligatoirement d'être imbriqués les uns dans les autres. Au contraire de l'exemple précédent, celui qui suit est syntaxiquement correcte.
<DATE>
<JOUR>26</JOUR>
<MOIS>08</MOIS>
<ANNEE>1973</ANNEE>
</DATE>
|
Enfin, sachez que tout document XML, doit et ne peut avoir qu'un seul tag racine. Tous les autres tags du document se devront d'être contenus dans le tag racine. L'exemple qui suit est encore une fois incorrecte.
<?xml version="1.0" ?>
<TAG-RACINE>
<!-- Contenu du tag -->
</TAG-RACINE>
<AUTRE-TAG-RACINE>
<!-- Contenu du tag -->
</AUTRE-TAG-RACINE>
|
Vous pouvez, en XML, injecter un (ou plusieurs) commentaire(s) dans vos fichiers XML. En fait, on introduit un commentaire de la même façon qu'en HTML. A savoir, tout commentaire commence par la séquence de caractères <!-- et se termine par la séquence -->. Ceux d'entre vous qui ont étudiés le chapitre précédent auront déjà été familiarisés avec cela.
Attention toute fois à ceux qui ont l'habitude du langage HTML. En effet, en HTML, tout tag non reconnu et purement et simplement ignoré. Certains ont donc pris la mauvaise habitude de commenter leurs fichiers en utilisant une construction de type <! commentaire >. Cela ne marche absolument pas en XML ! Une erreur sera renvoyée à qui utilisera une telle construction. Si c'est ce que vous faisiez, je ne peux que vous conseiller de changer vos habitudes (même en HTML).
L'exemple suivant vous montre un exemple de commentaires en tête d'un fichier XML.
<!-- --> <!-- Plan de cours sur le langage Visual Basic 6.0 --> <!-- --> <?xml version="1.0" encoding="ISO-8859-1"?> <?xml:stylesheet type="text/xsl" href="Formation.xsl" ?> <!DOCTYPE FORMATION SYSTEM "Formation.dtd"> <FORMATION> <TITRE>Visual Basic 6.0 (Niv 1 - Fr)</TITRE> <DUREE>5</DUREE> <!-- Suite du document --> </FORMATION> |
Une possibilité intéressante est à noter : vous pouvez mettre en commentaire un ensemble de tags. Syntaxiquement cela ne pose aucun problème étant donné que le commentaire se termine par la séquence --> : la fin d'un tag embarqué dans le commentaire ne le termine donc pas.
<?xml version="1.0" ?>
<EXEMPLE>
<!--
<DATE>
<JOUR>26</JOUR>
<MOIS>08</MOIS>
<ANNEE>1973</ANNEE>
</DATE>
-->
</EXEMPLE>
|
Le choix des tags pour définir un langage, n'est pas forcément trivial. De plus, on peut parfois exprimer des choses similaires via plusieurs structures différentes. En conséquence, il faut faire en sorte de choisir les alternatives les plus adaptées à vos besoins : Facile à énoncer, mais plus délicats à réaliser. Voici donc quelques conseils utiles à retenir.
En premier lieu, opter pour des nom de tags clairs et explicites, même s'ils sont plus long à saisir. Les choses n'en seront que plus lisibles : (1) à titre d'exemple, que veut dire <UL> en HTML ? En outre, c'est plus "mémo technique" : les utilisateurs retiendront plus vite les tags de votre langage.
Ensuite, réfléchissez bien à ce que vous devez faire des données comprises dans vos tags. Le choix de votre structure peut influer sur la suite des choses (comment récupérer les données dans une feuille de styles, par exemple). A titre d'exemple, regardez les deux propositions suivantes et dites moi laquelle est la meilleur ?
<DATE>26/08/1973</DATE>
ou
<DATE>
<JOUR>26</JOUR>
<MOIS>08</MOIS>
<ANNEE>1973</ANNEE>
</DATE>
|
En fait, il n'y a pas de meilleur solution dans l'absolu. Le choix dépendra de ce que vous voulez faire de vos dates. Mais si vous souhaitez les afficher tantôt d'une manière tantôt d'une autre, la seconde alternative est préférable. On pourra très simplement dissocier le jour du mois et de l'année. De plus le caractère de séparation n'est pas imposé dans la seconde alternative.
Même si ces discussions vous semblent secondaires, comprenez bien que c'est ce genre de choix qui fera la qualité de votre langage.
Si vous avez été, jusque là, très attentif, vous avez du voir qu'un tag pouvez aussi posséder des attributs. Ceux d'entre vous qui connaissent déjà HTML en ont l'habitude. Par exemple, la tag <TABLE>, permettant d'introduire un tableau dans le document, accepte un bon nombre d'attributs parmis lesquels : Border, CellSpacing, CellPadding, ...
En XML, les mêmes possibilités vous sont offertes. La syntaxe est la même que celle du langage HTML. Faites attention à ne pas utiliser les attributs de tags à tors et à travers. Ce sont ces points que nous allons maintenant développer.
Les différents attributs d'un tag sont obligatoirement fournis à la suite du nom du tag. Chaque élément (le nom du tag et le différents attributs) devant au moins être séparé des autres par un espace.
Un attribut de tag est constitué de deux parties : un nom et une valeur. La valeur doit être comprise soit entre des simples quottes soit entre des doubles guillemets. De plus, le nom est séparé de la valeur par le signe d'égalité.
<TagName attribut1="valeur1" attribut2='valeur2'>
Donnée du tag
</TagName> |
Souvent, vous serrez amené à faire des choix : certaines informations pourront être stockées soit sous forme de valeur d'attributs, soit sous forme de données de sous-tags. Le choix n'est pas toujours triviales. Pour vous en convaincre, analysez les deux exemples suivants : dans les deux cas, la date est bien découpée en trois parties constitutives (le jour, le mois et l'année). A votre avis, quel est le meilleur choix ?
<DATE>
<JOUR>26</JOUR>
<MOIS>08</MOIS>
<ANNEE>1973</ANNEE>
</DATE>
ou
<DATE jour="26" mois="08" année="1973" /> |
Normalement, un attribut vient qualifier la données d'un tag. Cela rajoute un complément d'information utile pour le traitement de la données. Mais un attribut ne doit pas contenir la donnée principale. Dans le cas d'une date, il est bien clair que l'information principale est constituée du jour, du mois et de l'année. Ces trois informations devraient donc normalement être des données de tags. La première alternative semble donc être préférable.
Malgré cela, et techniquement parlant, les deux alternatives permettraient de mettre en oeuvre une feuille de styles opérationnelle. J'espère que vous sentez bien les doutes auxquels vous pourriez être confronté dans l'avenir.
Pour clore cette section, je vous propose un dernier exemple. Celui-ci, ma fois, me semble tout à fait acceptable. Nous avons ici un tag permettant de définir une date, sous forme d'une unique données. Cependant, il se peut que vous ayez (par exemple dans une feuille de style) à décortiquer cette information pour la présenter différemment. Pour ce faire un attribut format vient compléter cette donnée en déterminant de quelle manière elle est constituée.
<DATE format="fr">26/08/1973</DATE> |
Il existe en XML deux attributs prédéfinis dont nous allons parler : il s'agit de xml:lang et xml:space. Il permettent, respectivement, d'indiquer la langue utilisée dans une partie du document et de dire ce que l'on va faire des caractères de séparation.
Dans les deux cas, il faut noter l'obligation de les redéfinir dans la DTD si vous souhaitez utilisez un système de validation (malgré le fait qu'ils soient prédéfinies en XML). Autre remarque : si l'un de ces deux attributs est utilisé sur un tag, cet attribut et sa valeur seront aussi cascadés sur tous les sous-tags. Il est donc possible de ne spécifier qu'une unique fois l'attribut xml:lang (par exemple) pour tout le document : il suffit de le définir sur le tag racine.
Reprenons l'étude ces deux attributs un à un
xml:lang : permet de spécifier la langue utilisée par les données. Voici quelques exemples d'utilisation de cet attribut : notez la possibilité de définir son propre jargon (il est préfixé de x-). Cette possibilité peut, par exemple, servir aux moteurs de recherche pour mieux classifier les documents traités, et mieux renvoyer des résultats pour une recherche donnée.
<EXEMPLE xml:lang="fr">Aquarelle</EXEMPLE> <EXEMPLE xml:lang="en-GB">Watercolour</EXEMPLE> <EXEMPLE xml:lang="en-US">Watercolor</EXEMPLE> <EXEMPLE xml:lang="x-hacker">ceci est un bug</EXEMPLE> |
xml:space : cet attribut accepte deux valeurs. La valeur par défaut est "default" (ça tombe bien). La seconde valeur autorisée est "preserve". Dans ce dernier cas, les caractères de séparation seront préservés : les outils de traitement de données XML pourront ainsi les utiliser. Par caractères de séparation, on entend les espaces, les tabulations et les caractères de passage à la ligne.
Pour information : les outils de traitement de données XML (les parseurs XML), sur lesquels nous reviendrons ultérieurement dans ce cours, transforment un flux XML textuel en une arborescence en mémoire. Le fait de préserver les séparateurs augmente la taille, en mémoire, de cette arborescence, étant donné que des noeuds supplémentaires sont créés pour stocker les caractères de passage à la ligne entre deux tags. Il faut donc utiliser cet attribut avec sagesse.
Un document XML est constitué de deux parties : le prologue et l'arbre d'éléments. Nous avons, jusque là, bien parlé de la seconde partie : l'arbre d'éléments. On utilise cette terminologie car tout ensemble de tags XML peut être représenté sous forme arborescente. Nous allons maintenant nous focaliser plus sur la première partie : le prologue.
Le prologue n'est pas obligatoire, mais vivement recommandé (de part la recommandation XML 1.0). Il contient des informations utiles pour le traitement des données qui y sont contenues. Il est, de plus, subdivisé en plusieurs sous-parties.
La première ligne sert, principalement, à deux choses. Premièrement, via l'attribut version, elle permet d'indiquer la version du langage XML utilisé. Pour l'heure, il n'y a pas réellement de difficulté à ce niveau, pour la simple et bonne raison qu'il n'existe qu'une seule et unique version de la recommandation : la version 1.0. Voici un petit exemple montrant l'utilisation de l'attribut version : attention aux minuscules et aux majuscules.
<?xml version="1.0" ?> <!-- Suit l'arbre d'éléments --> |
Sa seconde grosse utilité est de pouvoir spécifier quel est le système d'encodage ayant servit à générer le fichier. A ce sujet, quelques explications complémentaires me semble les bien venues. Normalement, vos données vont être contenues dans un fichier dans un format textuel. Pour ce faire, vous allez utiliser un outil qui produira un fichier 8 bits. Or, les outils manipulant les données XML, travailleront eux, non pas en 8 bits mais avec la norme ISO-10646. Il va donc falloir que ces outils transforment les données contenues dans le fichier au format précédemment cité (c'est aussi le cas pour Internet Explorer).
Mais ce n'est pas tout. Les différents systèmes d'exploitation existant n'utilisent pas tous le même système d'encodage 8 bits. Vous avez certainement déjà reçu des mails ou les caractères accentués étaient parasités : celui qui vous a envoyé le message n'était, à coup sur, pas sur le même système d'exploitation que vous. Par contre, quasiment tous ces systèmes d'encodage possèdent un point commun : ils sont tous dérivés du système ASCII.
Le système ASCII (American Standard Code for Information Interchange) est en fait un table de correspondance qui aux 128 (27) première valeurs entières fait correspondre des caractères bien précis. Ainsi, ASCII associe au code 65 le caractère "A", au code 97 le caractère "a", ... Cette table de correspondance existe maintenant depuis de nombreuses années et l'on est forcé de constater que 128 caractères c'est trop peu. Avec le temps, de nombreuses autres tables de correspondance sont venues étendre ASCII à 256 caractères (28). Si vous utilisez un système d'exploitation Windows configuré pour la France, sachez que vous utilisez alors la table latine 1 : cette dernière est normalisée sous la référence ISO-8859-1.
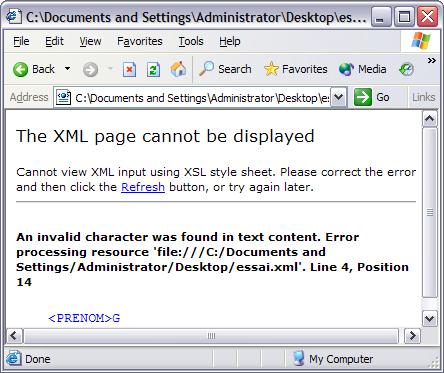
Si vous ne spécifiez rien, l'outil manipulant vos données (dans notre cas Internet Explorer) considérera que votre fichier utilise la norme ASCII. Or cette dernière ne contient pas de caractères accentués. Si dans vos données se trouve un seul et unique caractère accentué, le système affichera un message d'erreur. Regarder l'exemple suivant ainsi que la capture d'écran montrant le résultat dans Internet Explorer.
<?xml version="1.0" ?>
<PERSONNE>
<NOM>Durand</NOM>
<PRENOM>Gérard</PRENOM>
</PERSONNE> |
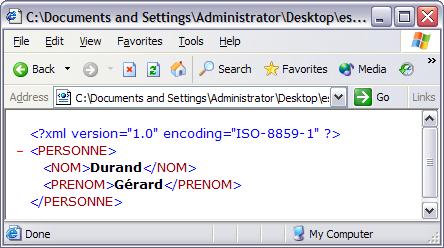
Si, au contraire, vous spécifier le système d'encodage ayant servit à générer le fichier, les données seront correctement interprétées, quel que soit le poste servant à la consultation. Pour spécifier le système d'encodage, utilisez l'attribut encoding. Analyser l'exemple suivant et la capture d'écran associée.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<PERSONNE>
<NOM>Durand</NOM>
<PRENOM>Gérard</PRENOM>
</PERSONNE> |
L'une des finalités de votre document XML est certainement de se présenter dans un navigateur. Pour ce faire, il faut le lier à une feuille de style. Comme nous l'avons déjà signalé dans le chapitre précédent, deux langages peuvent être utilisés : CSS (Cascading StyleSheet) ou XSL (eXtensible Stylesheet Language).
Pour effectuer la liaison, il vous suffit de rajouter la ligne, commençant par "<?xml:stylesheet" dans l'exemple suivant, en deuxième ligne du prologue. Cette ligne indique qu'on cherche à appliquer une feuille de styles. L'attribut type sert à spécifier le langage utilisé ("text/css" ou "text/xsl"). L'attribut href (Hypertext REFeference) indique la localisation du fichier.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<?xml:stylesheet type="text/css" href="Personnes.css" ?>
<PERSONNE>
<NOM>Durand</NOM>
<PRENOM>Gérard</PRENOM>
</PERSONNE> |
Le dernier aspect lié au prologue, dont nous allons parler, permet de lier une DTD (Document Type Definition) à votre document. Pour ce qui est des schemas, la liaison s'établit d'une autre manière. Nous reparlerons de cela bien plus tard.
Je rappelle qu'une DTD permet de définir une grammaire XML et que des outils de validation peuvent être utilisés pour contrôler la bonne utilisation des tags au sein d'un fichier de données. Le chapitre suivant rentrera plus en détail dans l'étude des DTD. Pour l'heure, ce qui nous intéresse, c'est de savoir lier une DTD à un fichier de données.
Cette liaison se réalise aussi au niveau du prologue, mais comparé aux lignes précédemment étudiées, la syntaxe diffère quelque peu. Il est aussi à noter qu'une DTD peut directement être embarquée dans le fichier de données. Dans ce cas, la DTD ne sert que pour cet unique fichier. Nous reparlerons de ces possibilités dans le chapitre suivant. Nous ne considérerons ici que le cas d'une DTD définie dans un fichier externe.
L'exemple qui suit vous montre comment la DTD est liée au fichier de données. Une remarque importante est à faire : le nom associé à la DTD doit être exactement identique au nom du tag racine, sans quoi une erreur vous sera retournée.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<?xml:stylesheet type="text/css" href="Personnes.css" ?>
<!DOCTYPE PERSONNE SYSTEM "Personnes.dtd" [] >
<PERSONNE>
<NOM>Durand</NOM>
<PRENOM>Gérard</PRENOM>
</PERSONNE> |
Maintenant que vous commencez à être à votre aise avec la syntaxe XML, je vais en profiter pour vous présenter, rapidement, d'autres aspects de syntaxe, quelque peu plus subtiles. Le concept principal à cerner étant la notion d'espaces de noms (namespace en anglais). Nous verrons ensuite comment injecter un sigle quelconque dans vos documents, dont certains sont fortement lié à la syntaxe XML (et notamment les caractères < et >).
Pour mieux comprendre la notion d'espace de noms, considérons un cas simple. Deux grammaires XML distinctes définissent des tags qui pourraient vous convenir. Dans ce cas, vous pouvez définir une grammaire qui inclue les deux langages précédemment cités.
Considérons aussi, que chacune des deux grammaires sur lesquelles vous vous appuyez définissent un même nom de tag, par exemple <DATE>, mais dont leurs utilisations et leurs significations seront différentes d'un langage à un autre. Dans ce cas, comment dire que l'on cherche à utiliser l'un des deux tags (étant donné qu'ils ont le même nom) ?
C'est, notamment, pour régler ce genre de problématique que la notion d'espaces de noms a été définie. Un nom, complet, de tag est en fait constitué de deux parties séparées par un caractère ":". La première partie spécifie dans quel espace de noms le tag est défini et la seconde nomme le tag. Normalement, un espace de nom est associé à une grammaire particulière. On peut donc ainsi envisager avoir les deux tags <FirstLanguage:DATE> et <SecondLanguage:DATE> sans risque de confusion.
Pour garantir l'unicité du tag, un espace de noms est généralement associé à une URL : en effet, chaque société possède bien sa propre URL. Ainsi, deux sociétés peuvent définir deux langages utilisant des tags similaires sans risque de conflits. Je ne sais pas si vous aviez déjà remarqué, mais nous avons déjà vu un exemple concret d'utilisation d'espace de noms. Si vous ne vous en souvenez pas, revenons rapidement sur la définition d'une feuille de styles XSL. Chaque tag du langage XSL est préfixé du qualificateur xsl. En fait, il s'agit d'un espèce d'alias que se substituera par l'URL http://www.w3.org/1999/XSL/Transform.
<?xml version="1.0" encoding="ISO-8859-1"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output encoding="ISO-8859-1"/> <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> <!-- Suite --> </xsl:stylesheet> |
Il est possible, dans un document XML, d'insérer n'importe quel caractère Unicode. En réalité, cela n'est pas complément vrai dans le sens ou XML supporte la norme ISO 10646 : mais cette dernière et Unicode sont très proche. Par en revenir à nos caractères, il est bien clair que votre clavier 102 touches aura du mal à vous permettre la saisie d'autant de caractères (aujourd'hui, plus de 38000 caractères sont définis dans la table Unicode).
Pour palier la difficulté, les concepteurs d'XML ont permis le fait de passer une chaîne de caractères ASCII particulière, afin d'obtenir un caractère donné. Cette chaîne de caractères doit commencer par la séquence "&#" et doit se terminer par le caractère ";". Entre ces deux parties, il vous faut fournir la valeur Unicode du caractère souhaité. Sachez aussi que la table Unicode repose, pour ces 128 premiers éléments sur la table ASCII.
Ainsi, l'exemple suivant permet d'insérer quelques caractères de l'alphabet grecque. Le résultat ici présenté ne s'affichera, malheureusement, pas correctement sous tous les navigateurs : seul le HTML des navigateurs modernes reconnaissent aussi cette possibilité.
<CONTENT>
Quelques caractères Grecque : Σ Π Φ Ω
</CONTENT> |
Quelques caractères Grecque : ? ? ? ? |
Enfin, pour clore ce chapitre, que quelque caractères posent, syntaxiquement, problème en XML. Lesquels, à votre avis ? En fait, ils sont au nombre de cinq, est sont tous fortement lié à la syntaxe XML. En effet, pour structurer votre flux XML, il vous faut, au moins, insérer des tags. Or, dans ce cas, comment insérer un caractère d'infériorité dans vos données ?
Pour ce faire, il vous faut utiliser la notion d'entité prédéfinie. Une entité est une construction XML syntaxique qui commence par le caractère "&" et qui se termine par le caractère ";" (comme pour l'injection de caractères Unicode). Le tableau suivant vous présente les cinq entités prédéfinies en XML, leur signification et le caractère associé. Vous auriez, bien entendu, pu utilisé le code Unicode correspondant à la place d'une entité prédéfinie.
< |
Less than | < |
> |
Greater than | > |
& |
Ampersand | & |
" |
Quote | " |
' |
Apostrophe | ' |
Il existe une autre manière d'injecter un contenu utilisant des caractères syntaxiquement importants pour XML : l'utilisation d'un bloc CDATA.
A l'intérieur d'un tel bloc, tous les caractères sont interprétés comme des simples caractères (y compris las caractères <, >, &,
' et ").
<tag><![CDATA[
if ( a < b && b > c ) {
// Do something
}
]]></tag>
Nous avons donc, au terme de ce chapitre fait un tour d'horizon des règles de syntaxe du langage XML. Pour ceux d'entre vous qui ont déjà manipulé HTML, notez que les choses sont bien différentes. En effet, alors que le langage HTML est laxiste et qu'il laisse passer les erreurs sans en alerter le lecteur, XML, par contre, vérifiera tous les points de syntaxe vus dans ce chapitre. La moindre entorse à ces règles engendrera un message d'erreur et terminera le traitement de la page.
Notons tout de même que les règles de syntaxes restent simples (très simples). Vous ne devriez donc pas rencontrer des problèmes insurmontables lors de la génération de vos fichiers de données.
Par contre, là où les choses se compliquent, c'est sur ce qui se rapporte à la grammaire de votre langage. C'est d'ailleurs de ces aspects dont nous allons commencer à parler dans le chapitre suivant, et plus particulièrement de la mise en oeuvre d'une DTD.
1 UL signifie Unordered List. En parallèle HTML fournit aussi le tag OL (Ordered List). Ils permettent respectivement de définir des listes à puces (non ordonnées) et des listes chiffrées (ordonnées).
Retour à la table des matières
Améliorations / Corrections
Vous avez des améliorations (ou des corrections) à proposer pour ce document : je vous remerçie par avance de m'en faire part, cela m'aide à améliorer le site.
Emplacement :
Description des améliorations :