

Bug

Links




ATTENTION : Tutorial en cours d'écriture ! N'hésiter pas à nous signaler toute erreur ou suggestion.
Dans le chapitre précédent, nous nous sommes surtout intéressé aux aspects de syntaxe inhérents au langage XML. Ce nouveau chapitre va être fortement complémentaire du précédent dans le sens ou nous allons maintenant nous intéresser à la définition d'une grammaire XML. En effet, même si vos tags sont correctement formatés, ce n'est pas pour autant que vous les avez utilisé correctement les un par rapport aux autres, relativement à leur sémantique.
Pour vous convaincre de l'utilité d'une grammaire, il vous suffit de penser au langage HTML. En effet, que pourrait vouloir signifier, dans ce langage, l'utilisation d'un tag <TR> (Table Row) à l'intérieur du couple de tag <A> utile pour la définition d'un lien hypertexte. Il est vrai qu'on ne peut, a priori, considérer une ligne de tableau que dans un tableau.
Pour valider que vos fichiers de données sont grammaticalement correcte, vous allez utilisez un langage de définition de grammaire XML. Aujourd'hui, il en existe deux. Le premier est le langage DTD (Document Type Definition) : historiquement, ce fut le premier proposé. Le second, initialement développé par la société Microsoft, est le langage de schemas (il s'agit en fait d'un langage XML dédié à la définition de grammaire). Nous allons, dans ce chapitre, nous focaliser uniquement sur la définition d'une DTD.
Avant de poursuivre plus en avant l'étude des DTD, quelques précisions et quelques définitions nous permettrons de mieux nous comprendre durant la suite de ce chapitre.
On parle de document bien formé quand il respecte bien toutes les règles de syntaxes XML. Au terme du chapitre précédent, nous sommes donc bien apte à définir des documents bien formés. En anglais vous retrouverez la terminologie suivante : "well-formed document".
Un document valide est obligatoirement bien formé : il respecte donc bien les différentes règles de syntaxe. Mais pour être valide, il doit de plus respecter une grammaire donnée. En anglais, vous retrouverez la terminologie suivante : "valid document".
Certains outils, plus ou moins simple, permettent de valider vos fichiers de données. Je ne peux, à ce niveau, que vous conseiller de jeter un coup d'oeil à l'outil XML Spy. Il s'agit d'ailleurs plus d'un environnement de travail, que d'un simple outil. Il est disponible à l'adresse http://www.xmlspy.com.
Sinon, d'autres outils plus simples peuvent être employés au niveau d'une console de commande. Sur plate-forme Windows, la société Microsoft en fournie une multitude. Notez au passage, que l'outil XML Spy (cité précédemment) utilise au final les commandes de bases Microsoft.
Il existe deux possibilités pour définir une DTD. Soit vous embarquez votre DTD au sein d'un fichier de données, soit vous pouvez la définir dans un fichier externe. Les deux techniques peuvent même être mixées. A votre avis, quelle est la meilleure solution ?
Il me semble logique de dire que la seconde alternative est préférable. En effet, il vous sera alors plus simple de partager votre DTD pour un ensemble de documents. On peut raisonnablement dire que si l'on définie une DTD (dit autrement, un langage), ce n'est pas pour un unique document.
Notons, dans les deux cas, que votre DTD va devoir être nommée. Ce nom se doit obligatoirement d'être celui du tag racine de vos fichiers de données (aux minuscules et majuscules près). Sans quoi une erreur vous sera retournée.
Si vous embarquez votre DTD dans un fichier de données, elle sera alors localisée dans le prologue, au niveau du tag <!DOCTYPE ...>. L'extrait de code suivant vous montre qu'elle est la syntaxe à utiliser. Notez que dans ce cas, le nom du tag racine du fichier XML doit obligatoirement être <exemple>.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE exemple [
<!-- début de la DTD -->
. . .
<!-- fin de la DTD -->
]>
<exemple>
<!-- Suite du document XML -->
</exemple>
|
La seconde possibilité permet de définir un fichier de validation externe que l'on pourra par la suite associé à plusieurs fichiers de données. Pour lier un fichier de données à une DTD, il vous faut aussi utiliser le tag <!DOCTYPE ... >. L'exemple qui suit vous montre un exemple de liaison. Le mot clé SYSTEM est utilisé pour indiquer ou se trouve la DTD : c'est une URL qui est attendue. Vous pouvez donc lier vos fichiers à une quelconque DTD présente sur le Web.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE exemple SYSTEM "fichier.dtd" []>
<exemple>
<!-- Suite du document XML -->
</exemple>
|
Nous allons maintenant voir le contenu de la DTD, à proprement dit, quelque soit sa localisation. En fait, une DTD définie plusieurs types de choses et notamment des tags et leurs règles d'imbrication, des listes d'attributs et des entités. Nous allons dans cette section nous focaliser sur la définition des tags.
A titre d'exemple, nous allons travailler sur un petit langage de définition de tableaux. En fait, je ne me suis pas compliqué la vie, j'ai simplement francisé les noms des tags HTML de définition de tableaux. Notre objectif est clair : définir une grammaire proche de celle du langage précédemment cité. L'exemple suivant montre un fichier de données illustrant l'utilisation de nos tags de définition de tableaux.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE TABLEAU SYSTEM "table.dtd">
<TABLEAU>
<TITRE>Titre du tableau</TITRE>
<LIGNE>
<CELL-E>\</CELL-E>
<CELL-E>Statistique 1</CELL-E>
<CELL-E>Statistique 2</CELL-E>
<CELL-E>Statistique 3</CELL-E>
</LIGNE>
<LIGNE>
<CELL-E>Expérience 1</CELL-E>
<CELL-D>25</CELL-D>
<CELL-D>34</CELL-D>
<CELL-D>75</CELL-D>
</LIGNE>
<LIGNE>
<CELL-E>Expérience 2</CELL-E>
<CELL-D>80</CELL-D>
<CELL-D>56</CELL-D>
<CELL-D>61</CELL-D>
</LIGNE>
</TABLEAU>
|
Pour ce qui est de la signification de nos tags, les choses sont simples. Pour les tags <TABLEAU>, <LIGNE> et <TITRE>, je ne m'y attarderai pas plus longtemps. Le tag <CELL-E> permet de définir des cellules d'entête (des cellules de titre) dans un tableau. Le tag <CELL-D> permet quant à lui de définir des cellules de données.
On peut noter principalement deux types de tags : ceux qui contiennent des données textuelles et ceux qui contiennent des sous tags. Le premier cas est clairement le plus simple à définir. Les règles suivantes définissent les tags de titres, de cellules d'entête et de cellules de données : en effet, chacun de ces tags ne contient que des données.
<!ELEMENT TITRE (#PCDATA)> <!ELEMENT CELL-E (#PCDATA)> <!ELEMENT CELL-D (#PCDATA)> |
Le mot clé ELEMENT permet d'indiquer que l'on cherche à définir un tag. Le mot clé #PCDATA indique, quant à lui, que ce tag contiendra des données : #PCDATA signifiant Parsed Character DATA.
Par contre, pour les deux autres tags (<LIGNE> et <TABLEAU>) les choses se compliquent un petit peu. Regardons dans un premier temps quelles sont les possibilités auxquelles nous avons droit. Dans un second temps nous verrons comment définir ces deux tags.
Plusieurs caractères vous sont proposés afin de pouvoir jouer sur l'occurrence d'un tag ou bien pour exprimer un choix. Le tableau suivant reprend ces caractères un à un et vous en donne leur signification
| ? | Occurrence : peut apparaître 0 ou 1 fois. |
| + | Occurrence : peut apparaître 1 ou plusieurs fois. |
| * | Occurrence : peut apparaître 0 ou plusieurs fois. |
| , | Séquence : Les deux parties doivent obligatoirement apparaître et dans cet ordre. |
| | | Choix : permet de choisir entre deux alternatives. |
| ANY | Choix : le tag peut contenir n'importe quoi. |
| EMPTY | Le tag ne peut strictement rien contenir. |
Afin de mieux les choses je vous propose d'analyser ces quelques petits exemples.
<!ELEMENT agenda (personne*) > |
Un agenda est constitué d'un nombre indéterminé de personnes |
<!ELEMENT personne (nom, prenom?, date)> |
Une personne doit posséder un nom puis un prénom (facultatif) puis une date de naissance |
<!ELEMENT hr (EMPTY) > |
En HTML, le tag HR (Horizotal Rule) est définie comme étant unitaire : il ne contient rien. |
Si nous revenons à notre exemple sur les tableaux les choses deviennent plus simples à exprimer. Pour ce qui est du tag <LIGNE>, il doit contenir un nombre indéterminé de cellules de données ou de cellules d'entête. Il nous faut donc cumuler deux caractères : celui de répétition * et celui de choix |. Mais attention à l'ordre dans lequel vous écrivez votre règle : les deux lignes suivantes ne disent pas la même chose. La première dit que l'on peut soit contenir un nombre quelconque de cellules de données soit un nombre quelconque de cellules d'entête. Alors que la seconde dit que l'on peut avoir un nombre quelconque de cellules. Chacune de ces cellules pouvant être soit une cellule de titre, soit une cellule de données. Il est clair que, si l'on veut fonctionner comme en HTML, la bonne règle est la seconde.
<!ELEMENT LIGNE (CELL-E* | CELL-D*) > <!ELEMENT LIGNE (CELL-E | CELL-D)* > |
Enfin pour la dernière règle, la plus compliquée de toute, nous allons chercher à dire qu'un tableau peut contenir un nombre quelconque de ligne, mais au plus un seul titre (ce dernier étant facultatif). Là, les choses se compliquent. Dans un tel cas, je ne peux que vous conseiller de casser le problème en sous-problèmes plus simples à traiter individuellement. En effet, un peut dire l'éventuel titre est soit en premier, soit au milieu des lignes ou bien à la fin. D'ou la règle suivante.
<!ELEMENT TABLEAU (( TITRE?, LIGNE*) |
(LIGNE*, TITRE?, LIGNE*) |
(LIGNE*, TITRE? )) >
|
Mais il est vrai que si l'on analyse bien ce que l'on vient d'écrire la première partie de la règle est un cas particulier de la seconde et idem pour la troisième partie. On peut donc simplifier cette règle. Au final, voici notre grammaire de définition de tableau.
<!ELEMENT TABLEAU (LIGNE*, TITRE?, LIGNE*) > <!ELEMENT LIGNE (CELL-E | CELL-D)* > <!ELEMENT TITRE (#PCDATA)> <!ELEMENT CELL-E (#PCDATA)> <!ELEMENT CELL-D (#PCDATA)> |
Un tag ne se limite pas uniquement à contenir des données ou des sous-tags. Il peut aussi contenir des attributs. Si vous cherchez à valider un fichier de données contenant des attributs de tags, il faudra impérativement qu'ils soient définis dans la grammaire (et donc dans notre DTD). Nous allons donc, dans cette section, voir comment définir une liste d'attributs associée à un tag.
Pour introduire une liste d'attributs, il faut utiliser le mot clé ATTLIST. Il est suivi du nom du tag et des données descriptives de chaque attribut. Il est a préciser que la syntaxe utilisée est, ma fois, pas réellement triviale : soyez donc consciencieux et séparez la définition de chaque attribut pas un retour à la ligne (il n'est pas requis mais sans lui la lecture en est très alourdie).
A titre d'exemple, nous allons rajouter des attributs à nos tags de définition de tableaux. Pour ce faire nous allons nous inspirer des tags HTML, tout en francisant les noms d'attributs. Le tag <TABLEAU> acceptera donc les attributs largeur et bordure et le tag <TITRE> se verra associé un attribut alignement. L'exemple suivant vous donne le code des deux listes d'attributs.
<!ELEMENT TABLEAU (LIGNE*, TITRE?, LIGNE*) > <!ATTLIST TABLEAU largeur CDATA "80%" bordure CDATA "1px" > <!ELEMENT LIGNE (CELL-E | CELL-D)* > <!ELEMENT TITRE (#PCDATA)> <!ATTLIST TITRE alignement (top | bottom) "bottom" > <!ELEMENT CELL-E (#PCDATA)> <!ELEMENT CELL-D (#PCDATA)> |
Reprenons ces définitions une par une. La première liste d'attributs est donc associée au tag <TABLEAU> et définit deux attributs. Le retour à la ligne n'est pas obligatoire et aucun caractère ne vient séparer les définitions : je vous conseille donc vivement de procéder ainsi. Trois informations viennent qualifier le premier attribut : il se nomme largeur, c'est une chaîne de caractères quelconque et par défaut sa valeur est de "80%". Vous pourriez me reprocher d'avoir utilisé le type CDATA pour cet attribut ! Pourquoi ne pas simplement dire que c'est un nombre ou un pourcentage ? Et bien par ce que ce n'est pas possible au niveau d'une DTD : soit nous avons une chaîne libre soit une valeur prise parmi une liste de valeur (nous y revenons dans quelques instants). Le second attribut se nomme bordure, c'est une chaîne quelconque et sa valeur par défaut est "1px".
La deuxième liste d'attributs est associée au tag <TITRE> et ne contient qu'une seule définition. Il s'agit de l'attribut alignement qui lui ne peut prendre qu'une des deux valeurs proposées : soit "top" soit "bottom". Sa valeur par défaut est "bottom". Notez bien que lorsque vous définissez la valeur par défaut, il faut la placer entre des doubles guillemets alors que lors des définitions de valeurs autorisées il ne faut surtout pas en mettre.
Dans l'exemple précédent, pour chaque attribut, nous avons fournit une valeur par défaut (au cas ou aucune valeur ne serait définie dans le fichier de données). Ce n'est pas la seule possibilité : cette section va en présenter d'autres. Mais notez, avant cela, que même si le navigateur ne valide pas par défaut votre document, il va quand même télécharger la DTD (sauf si elle est présente dans le cache de votre navigateur), car il en a besoin : en effet, sinon, comment aurait-il connaissance des valeurs par défaut utilisées par vos attributs ?
Si vous ne fournissez pas de valeurs par défaut, trois autres alternatives vous sont alors offertes. La première consiste à dire que la valeur de l'attribut est à fournir obligatoirement, ce via le mot clé #REQUIRED. Si un fichier de données contient un tag, pour lequel un attribut est obligatoire, et si aucune valeur n'est fournie alors le document générera un message d'erreur. Voici un exemple de définition d'attribut obligatoire.
<!ELEMENT DATE (#PCDATA) > <!ATTLIST DATE format (en | fr) #REQUIRED > |
<!-- La donnée est manipulable, car on qualifie son format --> <DATE format="fr">26/08/1973</DATE> |
La seconde alternative consiste à forcer un attribut à une valeur donnée. Dans ce cas, l'attribut existe bien. Sa valeur est imposée et l'utilisateur ne pourra en aucun cas changer cette valeur. Il ne sera même pas possible de spécifier l'attribut dans le fichier de données XML sans quoi une erreur sera retournée.
<!-- Comme le tag PRE en HTML --> <!ATTLIST PRE xml:space (default | preserve) #FIXED "preserve" > |
Enfin, la troisième alternative consiste à définir un attribut facultatif : attention, ce n'est pas la valeur qui est facultative (car fournie par défaut), mais bien l'utilisation de l'attribut. A titre d'exemple, citons l'attribut alt du tag <IMG> en HTML. Celui-ci permet de définir le texte alternatif de l'image : il apparaît, sous forme d'info-bulle, si vous laisser la souris immobile sur l'image pendant quelques instants. L'attribut est facultatif : s'il n'est pas fournit, aucune info-bulle n'apparaîtra (même pas une info-bulle sans texte).
<!ATTLIST MON-IMAGE alt CDATA #IMPLIED > |
Dans le chapitre précédent, nous avons parlé d'entités prédéfinies. Une entités est une construction XML qui commence par le caractère "&" et qui se termine par le caractère ";". Cinq entités sont prédéfinie en XML : il s'agit de "<", ">", "&", "&apos" et """.
Nous allons maintenant voir qu'il vous est aussi possible de définir vos propres entités. Cela vous permettra, en quelques sortes, de définir des alias que vous pourrez réutiliser par la suite. A titre d'exemple, considérons, encore, le langage HTML : "é", "à", ... sont des entités qui permettent d'insérer des caractères accentués dans un document.
Vos entités commenceront elles aussi par le caractère "&" et se termineront aussi par le caractère ";". Et vous pouvez définir deux types d'entités : les entités internes et le entités externes. Etudions de plus près chacune de ces possibilités.
Une entité est qualifiée d'interne si sa définition est directement embarquée dans la DTD : c'est le cas le plus simple. Son intérêt consiste à pouvoir remplacer autant de fois que nécessaire l'entité par le texte qui lui est associé. Si vous êtes programmeur C, vous pouvez comparer ce mécanisme à l'instruction #define du pré-processeur C.
L'exemple suivant vous montre comment définir une entité. Notez au passage que le texte de l'entité peut être complexe : il peut contenir des tags, pourvu que la grammaire soit bien respectée après la substitution.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE test [
<!ENTITY titre "Introduction au langage XML" >
<!-- . . . -->
]>
<test>
&titre;
</test>
|
Encore une fois, j'insiste sur le fait que même si le navigateur ne valide pas par défaut votre document, il est malgré tout obligé de télécharger la DTD (si elle est externe, bien entendu) : c'est elle qui contient les définitions des entités, et le navigateur devra bien les remplacer.
Le second type d'entités que vous pouvez définir permet de substituer au nom de l'entité un contenu localisé dans un autre fichier. Afin de mieux comprendre le concept, étudions un petit exemple simple. Nous avons deux fichiers XML : chacun de ces fichiers définit un chapitre d'un livre. Bien entendu, un chapitre étant complexe, il est donc structuré via des tags adaptés. Voici un exemple de contenu pour un tel fichier (j'ai volontairement tapé n'importe quoi pour chacune des sections).
<?xml version="1.0" encoding="ISO-8859-1" ?>
<chapitre>
<titre>le titre du chapitre 1</titre>
<section>sqgkfjsmqdlks fqjlf</section>
<section>sqgkfjsmqdlks fqjlf</section>
<section>sqgkfjsmqdlks fqjlf</section>
</chapitre>
|
Maintenant regardons le contenu du fichier "bouquin.xml" : par l'intermédiaire d'entités externes, il rassemble le contenu des deux fichiers de chapitre en un unique document XML. Une autre entité interne y est aussi présente. Notez bien la présence du mot clé SYSTEM utilisé pour signifier que le contenu de l'entité, à l'instar de la déclaration d'une DTD, est localisé dans un autre fichier.
<?xml version="1.0" ?>
<!DOCTYPE bouquin [
<!ENTITY chapitre-1 SYSTEM "./chapitre1.xml">
<!ENTITY chapitre-2 SYSTEM "./chapitre2.xml">
<!ENTITY auteur "Dominique LIARD">
]>
<bouquin>
<titre>XML blabla</titre>
<auteur>&auteur;</auteur>
&chapitre-1;
&chapitre-2;
</bouquin>
|
La capture d'écran qui suit vous montre ce qu'affiche le navigateur Internet Explorer si on lui demande d'affiché le document maître "bouquin.xml".
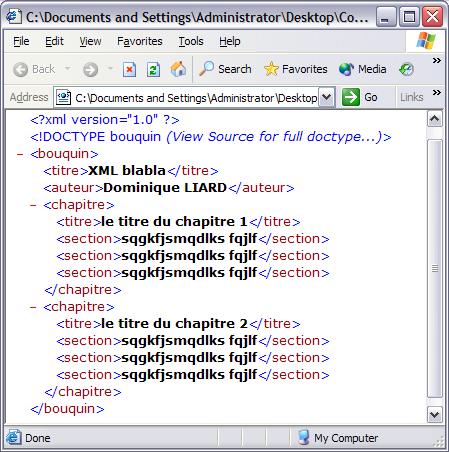
Au terme de ce chapitre, la déclaration d'une DTD ne devrait quasiment plus avoir de secrets pour vous. Nous avons en effet vu comment définir les tags qui vont constituer votre grammaire, ainsi que leurs règles d'utilisation. Nous avons ensuite étudié comment ajouter des attributs aux tags de votre grammaire. Enfin, nous avons détaillé la manière de définir vos entités : qu'elles soient internes ou externes.
Comme nous l'avons déjà dit précédemment, le langage de définition de DTD n'est pas le seul mécanisme dont vous disposiez. En effet, les schémas XML (une autre recommandation du W3C) permettent aussi de faire de même. C'est justement ces aspects que nous allons développer dans le chapitre suivant.
Retour à la table des matières
Améliorations / Corrections
Vous avez des améliorations (ou des corrections) à proposer pour ce document : je vous remerçie par avance de m'en faire part, cela m'aide à améliorer le site.
Emplacement :
Description des améliorations :