Introduction de l'utilisation de JPA
Accès rapide :
La vidéo
La persistance des données avec Java EE
Un premier exemple d'utilisation de JPA
La base de données utilisée
La classe Article
Le mapping JPA
La configuration de votre moteur de persistance
Utilisation de l'API JPA
La vidéo
Cette vidéo vous présente l'API JPA (Java Persistence API) incluse dans les spécifications Java/Jakarta EE.
JPA précise les modalités de fonctionnement d'un ORM (Object Relational Mapping) Java à base d'annotations.
Plusieurs implémentations JPA existent (OpenJPA, Eclipse Link et Hibernate) : nous utiliserons Hibernate.
Introduction de l'utilisation de JPA
La persistance des données avec Java EE
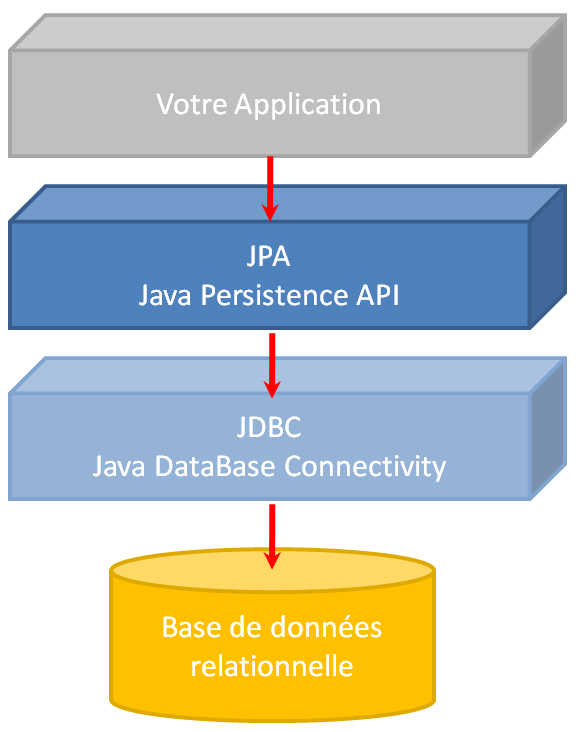
Java SE permet déjà de synchroniser des données dans une base de données relationnelle : pour ce faire vous pouvez utiliser l'API JDBC
(Java DataBase Connectivity). Vous pouvez consulter notre tuto à ce sujet.
Pour autant, on peut considérer JDBC comme une API de bas niveau. La plate-forme JEE (Java EE ou dorénavant Jakarta EE) propose une couche d'abstraction
par-dessus JDBC : JPA (Java Persistence API). Bien entendu JPA ne permet d'adresser qu'à des bases de données relationnelles (à l'instar de JDBC).
En fait JPA est une spécification d'ORM (Object Relational Mapping) pour Java. Un ORM, comme son nom l'indique, permet de faire le lien entre le
monde objet et le monde de la base de données relationnelle. Un ORM doit permettre de produire automatiquement les ordres SQL relatifs aux actions
CRUD (Create/Read/Update/Delete) sur vos objets et de les engager en base de données.
Il existe des ORM pour quasiment tous les langages de programmation et donc aussi pour Java.
JPA étant une spécification (dit autrement un PDF), il en existe plusieurs implémentations. Les trois plus connus sont Hibernate (RedHat),
Eclipse Link (de la fondation Eclipse, vous vous en doutez) et Open JPA (de la fondation Apache). Le serveur Glassfish, que nous avons choisit
d'utiliser, embarque l'implémentation Eclipse Link.
Les intérêts à utiliser un ORM compatible JPA sont les suivants :
Abstraction quasi totale du langage SQL : c'est le rôle de l'ORM de produire le code SQL équivalent à vos actions.
Indépendance vis-à-vis de la base de données utilisée : comme vous ne produisez pas le code SQL, vous n'êtes pas lié à une base de données
précise. Les ORM JPA peuvent travailler sur toutes les bases de données manipulables par JDBC. Vous êtes donc libre de changer votre SGBDr
(Système de Gestion de Base de Données relationnel) à tout moment.
Meilleure productivité : comparer à JDBC, vous avez beaucoup moins de code à produire (et notamment avec le SQL).
Risque d'injection SQL fortement réduit : vu que vous ne produisez plus de codes SQL, vous évitez un grand nombre d'attaques basées sur
une mauvaise utilisation de ce langage.
Par contre, il y a des risques à utiliser JPA :
JPA consiste en une surcouche logicielle par-dessus JDBC : ça peut donner lieu à plus de code à exécuter.
Les concepts proposés par JPA sont de très haut niveau et relativement subtils (cache de données, lazy loading, ...) : mal utilisés,
ces mécanismes peuvent fortement dégrader les performances de vos programmes.
Il est donc impératif de bien maîtriser votre ORM afin d'éviter des gros pièges.
Un premier exemple d'utilisation de JPA
Nous allons commencer par un premier exemple très simple d'utilisation de JPA : nous allons chercher à mapper une table, en base de données, contenant
des articles à une classe Article. Dans un premier temps, nous allons travailler hors d'un serveur d'applications JEE.
Nous allons juste lancer un programme Java, utilisant JPA, en mode console. Comme nous serons hors d'un serveur d'applications, nous n'aurons pas accès
par défaut, à une implémentation JPA. Il faut donc en télécharger une. Je vous propose d'utiliser Hibernate. Veuillez aller sur le site
http://www.hibernate.org pour télécharger le logiciel. Il est constitué d'un certain nombre
de fichiers Jar (normalement, vous avez le logiciel ainsi que toutes les dépendances requises à son fonctionnement).
Veuillez créer un nouveau projet Java et ajouter l'ensemble des fichiers Jar au CLASSPATH (au build path, si vous utilisez Eclipse).
N'oubliez pas non plus de prendre le jar associé au driver JDBC de votre base de données (JPA est une sur-couche à JDBC).
La base de données utilisée
Pour ce qui est de la base de données, nous allons rester sur celle déjà utilisée durant les chapitres précédents. Pour rappel, nous avons utilisé
le serveur MariaDB et nous y avons créé une petite base de données pour un site de vente en ligne. Dans ce chapitre nous allons nous intéresser
uniquement à la table T_Articles stockant les articles proposés. Pour rappel, voici le code SQL utilisé pour sa création.
CREATE TABLE T_Articles (
IdArticle int PRIMARY KEY AUTO_INCREMENT,
Description text NOT NULL,
Brand text NOT NULL,
UnitaryPrice double NOT NULL
);
La classe Article
Il nous faut maintenant produire une classe Java permettant la manipulation des articles. Nous allons repartir de la classe proposée dans un
précédent tuto dédié à JDBC. En voici son code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
package fr.koor.webstore.business;
public class Article {
private int idArticle;
private String description;
private String brand;
private double price;
public Article() {
this( "unknown", "unknown", 0 );
}
public Article( String description, String brand, double price ) {
this.setDescription( description );
this.setBrand( brand );
this.setPrice( price );
}
public int getIdArticle() {
return idArticle;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Article [idArticle=" + idArticle + ", description=" + description +
", brand=" + brand + ", price=" + price + "]";
}
}
|
Une classe de manipulation d'articles
Le mapping JPA
Nous allons maintenant traiter de la partie la plus importante : le mapping JPA. C'est lui qui va faire le lien entre le monde de la base de données
et le monde Objet. Ce mapping se définit sur votre classe grâce à un jeu d'annotations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package fr.koor.webstore.business;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity @Table( name="T_Articles" )
public class Article {
@Id @GeneratedValue( strategy=GenerationType.IDENTITY )
private int idArticle;
private String description;
private String brand;
@Column( name="UnitaryPrice" )
private double price;
// La suite de la class ...
}
|
Ajout du mapping JPA
L'annotation @Entity dit que la classe Article est soumisse à persistance : c'est une entité persistante.
L'annotation @Table permet de spécifier le nom de la table (en base de données) dans laquelle nos instances d'articles devront
être persistées. A défaut, la table doit avoir le même nom que la classe.
L'annotation @Id indique que l'attribut idArticle de votre classe est « mappé » (mis en correspondance,
si vous préférez) à la colonne de clé primaire en base de données. Comme aucune annotation @Column n'est ajoutée à l'attribut
idArticle, la colonne doit avoir exactement le même nom. L'annotation @GeneratedValue indique que le moteur de
base de données à la responsabilité de générer les nouvelles valeurs pour la clé primaire en cas d'insertion de nouveaux objets.
Par défaut, un attribut est mappé à une colonne de même nom en base de données. C'est le cas pour description et brand.
Si vous ne souhaitez pas mapper un attribut, indiquez-le via l'annotation @Transient.
L'annotation @Column utilisée pour le prix de vos articles permet d'indiquer le nom de la colonne correspondante en base de données,
étant donné que les deux noms ne correspondent pas.
Il faut savoir que vous auriez pu définir votre mapping directement sur les propriétés (les getters/setters) plutôt que sur les attributs.
JPA supporte les deux possibilités. Dans ce cas, placez les annotations devant les getters (getIdArticle et getPrice).
Lors d'un chargement d'une entité à partir de la base de données, l'objet en mémoire aurait été initialisé en passant par les setters.
Lors de la sauvegarde d'une entité, la récupération de l'état aurait été faite via les getter. Dans notre cas (mapping sur attributs), Hibernate
accédera directement aux attributs de nos articles.
Pour une classe donnée, soit vous annotez les attributs, soit vous annotez les propriétés (getters/setters). En cas de mix entre les deux possibilités,
c'est l'annotation @Id qui permettra de trancher sur la stratégie à appliquer. Les annotations non cohérentes par rapport au positionnement
de @ID seront purement et simplement ignorées.
La configuration de votre moteur de persistance
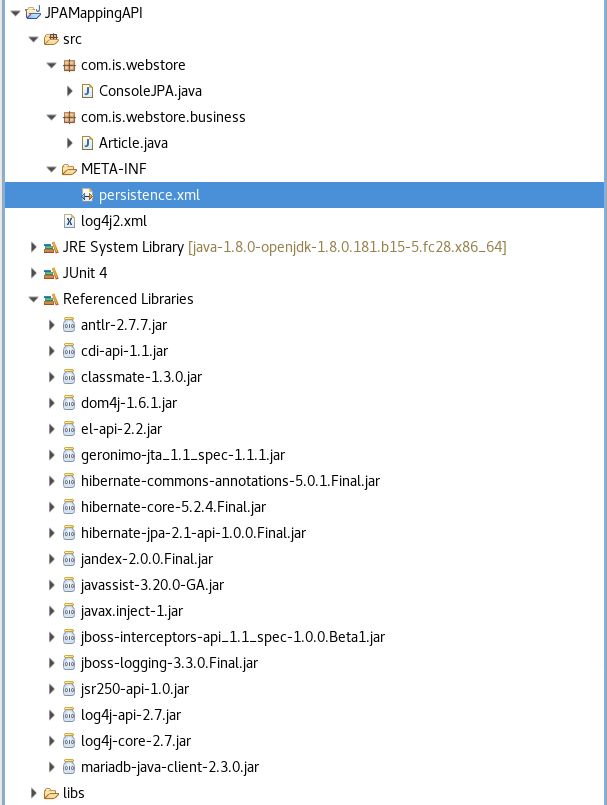
Pour que votre moteur JPA puisse correctement fonctionner, il est nécessaire de le configurer : cela se fait via le fichier
META-INF/persistence.xml. Ce fichier doit être accessible à partir du CLASSPATH : sous Eclipse, cela veut dire que le dossier
META-INF doit être localisé dans votre dossier src, comme le montre la capture d'écran ci-dessous.
Et voici le contenu de ce fichier de configuration :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="WebStore">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>fr.koor.webstore.business.Article</class>
<properties>
<property name="javax.persistence.jdbc.driver" value="org.mariadb.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost/WebStore" />
<property name="javax.persistence.jdbc.user" value="#user#" />
<property name="javax.persistence.jdbc.password" value="#password#" />
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect" />
</properties>
</persistence-unit>
</persistence>
|
Fichier de configuration JPA : META-INF/persistence.xml
bien entendu, veuillez remplacer les chaînes de caractères #user# et #password# par vos propres identifiants.
La ligne correspondant au « provider » est, bien entendu, dépendante de l'implémentation JPA retenue (Hibernate dans notre cas).
Voici les chaînes de définitions associées aux principales implémentations :
| Nom de l'implémentation JPA |
Configuration du provider |
| Hibernate (RedHat) |
org.hibernate.jpa.HibernatePersistenceProvider |
| Eclipse Link |
org.eclipse.persistence.jpa.PersistenceProvider |
| Open JPA |
org.apache.openjpa.persistence.PersistenceProviderImpl |
Utilisation de l'API JPA
Et voici maintenant un exemple de code JPA utilisant les quatre opérations CRUD sur nos articles.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
package com.is.webstore;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import com.is.webstore.business.Article;
public class ConsoleJPA {
public static void main(String[] args) throws Exception {
EntityManagerFactory entityManagerFactory = null;
EntityManager entityManager = null;
try {
entityManagerFactory = Persistence.createEntityManagerFactory("WebStore");
entityManager = entityManagerFactory.createEntityManager();
System.out.println( "- Lecture de tous les articles -----------" );
List<Article> articles = entityManager.createQuery( "from Article", Article.class )
.getResultList();
for (Article article : articles) {
System.out.println( article );
}
System.out.println( "- Insertion d'un nouvel article ----------" );
EntityTransaction trans = entityManager.getTransaction();
trans.begin();
Article newArticle = new Article( "DBS", "Aston Martin", 200000 );
entityManager.persist( newArticle );
List<Article> results = entityManager.createQuery("from Article", Article.class).getResultList();
for( Article article : results) {
System.out.println( article );
}
System.out.println( "- Modification d'un article --------------" );
newArticle.setPrice( 40000 );
entityManager.persist( newArticle );
results = entityManager.createQuery("from Article", Article.class).getResultList();
for( Article article : results) {
System.out.println( article );
}
System.out.println( "- Suppression d'un article ---------------" );
entityManager.remove( newArticle );
results = entityManager.createQuery("from Article", Article.class).getResultList();
for( Article article : results) {
System.out.println( article );
}
trans.commit();
} finally {
if ( entityManager != null ) entityManager.close();
if ( entityManagerFactory != null ) entityManagerFactory.close();
}
}
}
|
Utilisation de l'API JPA








 Définition d'un template pour vos facelets
Définition d'un template pour vos facelets
 JPA et la journalisation avec Hibernate
JPA et la journalisation avec Hibernate
Améliorations / Corrections
Vous avez des améliorations (ou des corrections) à proposer pour ce document : je vous remerçie par avance de m'en faire part, cela m'aide à améliorer le site.
Emplacement :
Description des améliorations :